



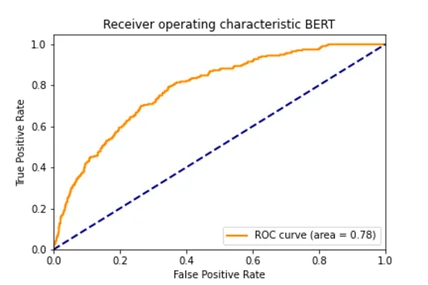
서울대학교 병원 질병 예측
#자연어처리 #질환 예측 #서울대병원

와
늘 믿고 맡깁니다 감사합니다

K54*****
세 번째 의뢰인데 이번에도 만족스럽습니다. 매번 감사드려요!
데이터 기반의 혁신적인 자연어 처리(NLP) 및 딥러닝 솔루션으로 비즈니스를 성장시키세요. 저희 팀은 고객의 텍스트 데이터를 활용하여 맞춤형 서비스를 개발해드립니다. 자체 데이터가 없는 경우에도 공공데이터를 활용한 모델 개발이 가능합니다. 상담을 통해 여러분의 요구 사항을 파악하고 최적의 솔루션을 제안해 드립니다.
서비스 포인트:
- 최신 딥러닝 기반 자연어 처리 모델
- 맞춤형 솔루션 개발
- 다양한 언어 및 도메인 지원
- 전문적인 지원 및 빠른 응답
주요 서비스:
- 감정 분석 (긍정/부정 판단)
- 텍스트 분류 (글의 카테고리 판단 등)
- 개체명 인식 (NER)
- 키워드 추출
- 텍스트 요약 및 생성
- 음성인식 프로그램 개발
진행 프로젝트:
- 제약 분야 기사 분류, 개체명 인식(NER), 요약 프로그램 개발
- 소설 요약 및 생성 프로그램 개발 (BART 활용)
- 논문 및 특허 요약 및 키워드 추출 프로그램 개발
- 특허 검색 프로그램 개발 (Sentence Transformer 활용)
- 한국어 연구용 음성인식 프로그램 개발
- 환자 음성인식 프로그램 개발 - 전북대 병원
- 진단서를 통한 수술 여부 예측 - 서울대 병원
서비스 진행 절차:
- 상담 및 요구사항 분석: 무료 상담을 통해 고객의 요구사항을 파악하고 최적의 솔루션을 제안합니다.
- 데이터 준비: 고객의 데이터를 분석하고, 필요한 경우 공공데이터를 활용하여 모델 개발을 시작합니다.
- 모델 개발 및 최적화: 최신 자연어 처리 기술을 활용해 고객의 요구에 맞는 모델을 개발하고 최적화합니다.
- 결과 검증 및 수정: 개발된 모델의 결과를 검증하고, 필요한 경우 수정 작업을 진행합니다.
- 최종 배포 및 지원: 완성된 모델을 고객에게 전달하고, 필요한 경우 추가적인 지원을 제공합니다.
지금 바로 연락해 주시면 무료 상담을 진행해 드립니다. 여러분의 비즈니스를 성장시키는 최적의 자연어 처리 및 딥러닝 솔루션을 함께 만들어 가겠습니다. 이제, 여러분의 비즈니스에 혁신을 가져올 기회를 잡으세요!
상담 과정에서 가지고 계신 데이터와 만들고자 하시는 서비스를 전달해주시면 검토 후 진행 여부를 결정합니다.
진행하기로 결정한 경우 데이터 전처리 및 모델 개발, 데이터 학습 후 원하시는 형태로 모델을 제공해 드립니다.
전달해 드리는 코드는 전처리 코드, 자연어 처리 모델 로 코드 활용법 설명 파일을 함께 제공해드려 사용에 어려움이 없도록 해드립니다.
만들고자 하시는 서비스에 대해 구체적인 계획이 있거나 함께 상담을 통해 구체화 할 수 있을 정도의 계획이 있으면 좋습니다. 기술적으로 정보가 부족하여 구체화 하지 못하신 부분은 제가 채워드립니다.
이와 관련하여 현재 가지고 있는 데이터 또는 향후 수집할 계획이 있는 데이터에 대한 정보를 부탁드립니다.
기술 수준
팀 규모
상주 여부
개발 언어
다양한 자연어처리 프로그램 개발
- 데이터 전처리 진행 - 유수의 기업(구글, 페이스북 등)에서 활용하는 인공지능 모델 개발
시나리오 개수
1개
그래프 / 차트
2개
모델링 종류
1개
작업일
14일
수정 횟수
2회

총 작업개수
41건만족도
100%회원구분
기업회원세금계산서
발행가능DPiper 대표 데이터 바우처 지원 사업 공급기업 자연어처리(NLP) 모델 개발 및 API 배포
작업물을 전달드려 수령하신 이후에 추가로 2회의 수정이 가능합니다. 수정 범위는 아래와 같습니다 - 프로젝트 진행 이후에 추가로 데이터를 수집하시거나 생성하신 경우 해당 데이터를 포함한 추가 학습 - 프로젝트의 성능을 확인할 수 있는 성능 지표가 추가로 필요한 경우 해당 성능 지표 그래프/차트 추가 모델 자체 변경, 학습 방법 변경 등 작업물에 많은 변경이 필요한 경우는 수정의 범위에 해당하지 않습니다.
가. 기본 환불 규정 1. 전문가와 의뢰인의 상호 협의하에 청약 철회 및 환불이 가능합니다. 2. 작업이 완료된 이후 또는 자료, 프로그램 등 서비스가 제공된 이후에는 환불이 불가합니다. ( 소비자보호법 17조 2항의 5조. 용역 또는 「문화산업진흥 기본법」 제2조 제5호의 디지털콘텐츠의 제공이 개시된 경우에 해당) 나. 전문가 책임 사유 1. 전문가의 귀책사유로 당초 약정했던 서비스 미이행 혹은 보편적인 관점에서 심각하게 잘못 이행한 경우 결제 금액 전체 환불이 가능합니다. 다. 의뢰인 책임 사유 1. 서비스 진행 도중 의뢰인의 귀책사유로 인해 환불을 요청할 경우, 사용 금액을 아래와 같이 계산 후 총 금액의 10%를 공제하여 환불합니다. 총 작업량의 1/3 경과 전 : 이미 납부한 요금의 2/3해당액 총 작업량의 1/2 경과 전 : 이미 납부한 요금의 1/2해당액 총 작업량의 1/2 경과 후 : 반환하지 않음
| 서비스 제공자 | DPipe | 취소/환불 조건 | 취소 및 환불 규정 참조 |
| 인증/허가사항 | 상품 상세 참조 | 취소/환불 방법 | 취소 및 환불 규정 참조 |
| 이용조건 | 상품 상세 참조 | 소비자상담전화 | 결제 전 상담 제공 |
4.9
(26)