







텍스트마이닝 토픽모델링 논문/연구용 시각화
#텍스트마이닝 #토픽모델링 #LDA #CONCOR #연구동향



통*****
빅데이터 기반 통계가 어려워서 어떻게 해야할지 막막한 참에 전문가님의 도움을 받게 되어 너무 수월하게 네트워크분석과 토픽모델링을 진행할 수 있었습니다! 제가 문의도 많이 하고 여러번 요청드리기도 했었는데 항상 빠르게 답변해주시고 모두 친절하고 자세하게 알려주셨어요:) 특히 통계에 기본 지식이 약하다보니까 결과를 보고도 해석이 어려웠는데 해석까지 제가 이해할 수 있도록 잘 설명해주셔서 통계를 잘 모르는 제가 봐도 이해하기 쉽도록 도와주셨어요. 또 중간중간 제가 확인하고 체크할 수 있도록 진행상황을 공유해주시고 수정할 부분이나 제가 요청한 부분과 일치하는지를 확인해주신 부분이 좋았어요. 왜 리뷰가 많고 좋은지 경험해보면서 알게되고 확신을 가지며 맡길 수 있게 되었던 것 같아요. 통계하면 전문가님이 최고인 것 같습니다 !! 덕분에 좋은 배움을 얻고 갑니다. 감사합니다.
(18)
대학교수,대기업,정부기관도 의뢰하는 업체
생성AI기반 빅데이터분석/텍스트마이닝에 진심인 해피AI입니다!
해피AI는 [크몽 Prime 서비스]입니다.
크몽에 등록된 11618개의 서비스 중 프라임 서비스는 157개 입니다.
(2024년11월 기준)
"고품질"의 결과물이 아니면 비용을 받지 않겠습니다.
"고품질" 결과물을 원하시는 분들만 의뢰해주시기 바랍니다.
-------------------
# 7년간 300건 이상 텍스트마이닝/LLM기반 빅데이터 분석 프로젝트 진행(만족도 100%)
※ 주의!! "고품질 결과 "제공을 위해 매달 제한된 양의 주문만 받고 있습니다.
# 1월 프로젝트 선착순 2건 : 현재 1건 의뢰 가능(주의! 마감 시 가격이 상승)
-------------------
"기법이나 원리가 동일하다고 해서 동일한 결과와 해석을 얻는게 아닙니다. 어디에 맡기느냐에 따라 그 결과와 해석이 완전히 달라집니다."
"해피AI는 4년 이상 인문사회계열 연구자를 대상으로 만족스런 빅데이터 분석 및 텍스트 마이닝 서비스를 제공해왔습니다. 또한 삼성, 서울시, 서울대 등 국내 여러 대기업 및 정부기관,대학교와 협력하여 생성 AI 기반 빅데이터 ,AI 프로젝트들을 성공적으로 수행하며 대외적으로 전문성을 인정받아 왔습니다. 해피AI는 생성AI 기반 빅데이터 분석 분야에서 지속적으로 성장하고 있는 업체입니다."
"해피AI 대표는 석사는 인문학, 박사는 AI 전공으로 정부기관, 대기업, 대학 등 300회 이상의 AI 및 빅데이터 분석 프로젝트를 진행해오며 쌓아온 모든 노하우를 담아 원하시는 목적의 결과를 얻을 수 있도록 최대한 도와드립니다."
(해피AI 대표소개) https://drive.google.com/file/d/1-72BSpUm0Pmb1NJpmyRJ9Xljp5pNgDGJ/view
"해피AI는 고전 모델이 아닌 최근 트렌드인 생성AI를 활용한 SCI급의 정밀한 분석기법을 적용하고 깊이있는 해석도 제공해 드립니다."
(해피AI 언론보도 자료)
https://www.psnews.co.kr/news/articleView.html?idxno=2066949
"해피AI는 LLM기반의 정밀한 빅데이터 분석과 섬세한 해석, 시각화를 통해 보고서 작성까지 완벽하게 지원하기 때문에, 정부 및 공공기관 연구자들이 정책 연구 시 많이 찾고 애용하는 서비스입니다 (빅데이터 해석+시각화가 포함된 정책 연구보고서 제공) "
"인문사회과학 관련 대학원생,연구원님,교수님들의 논문/연구보고서에 요즘 트렌드인 생성 AI를 활용한 텍스트마이닝 기법을 적용하고 깊이 있는 해석도 제공해 드립니다(데이터+해석+시각화) "
" 연구논문/연구보고서에 쓰이는 데이터 해석의 경우 Defence걱정 없도록 분석 기법을 적용하고 꼼꼼하고 세심하게 해석을 제공해드립니다. 데이터 해석의 경우 수백번 진행한 연구 컨설팅을 통해 축적된 노하우로 심사의견을 방어할 수 있게끔 여러번 피드백을 드리며 완성해 드리기 때문에 학위,학술논문을 쓰는 대학원생은 물론 정책연구,국가과제, 기업과제를 진행하시는 대학교 교수님,정부출연기관 연구원님, 대기업 담당자 분께서 대단히 만족해하시고 여러 번 의뢰해주시고 계십니다."
"원하시는 기법이 있는 국내외 논문들을 제공해주시면, 연구 목적에 알맞게 적용후 분야에 맞게 해석도 제공해 드립니다"
" TEXTOM, 파이썬(Python)기반의 텍스트마이닝 기법을 활용한 분석은 물론이며 최신 AI모델 기반의 심화 분석기법을 적용해 논문의 가치를 높여 드립니다 (인문 사회과학 논문 작성 시 추천!)"
#(24년 12월 기준) 본 서비스로 약 180명의 석박사 대학원생, 대학교수, 국책연구기관 연구원분들의 탑티어급 학회지 논문 투고를 도와드렸습니다.
# (24년 12월 기준) 현재 약 30개의 정부출연 산하기관, 대학교, 대기업에 서 진행하는 생성AI기반 빅데이터 분석 프로젝트 및 연구 진행을 도와드렸습니다.
이왕 비용 들이는 만큼 돈 아깝다는 마음 들지 않게 해드리겠습니다!
해피AI를 찾아오는 고객분들 대다수가 절실하면서 난관에 처해 있기에, 최대한 진심으로 친절하게 응대해 드립니다.
제가 한 만큼 다시 되받는다는 걸 알기에 진정성 있게 도움 드리겠습니다!
서비스 비용은 데이터의 규모와 난이도,기한에 따라 조정됩니다
(기업이나 기관의 정책 연구 프로젝트도 진행 가능합니다!)
-------------------
[경력]
(현) 생성AI 및 생성 AI 기반 빅데이터 분석 전문기업 해피AI 대표(24~)
(현)동국대학교 AI대학원 박사과정 수료(22~자연어처리 및 LLM 전공)
(현)퍼블릭 뉴스 AI 및 빅데이터 분석 칼럼니스트 (23~)
(전) 전 정부출연산하연구기관 자연어처리/빅데이터 분석 연구원 (18~21, 인문사회과학 연구)
(전)자연어처리 /빅데이터 전문기업 Textom 최우수 Anlayst(’21~’22,인문사회과학 데이터 분석)
(전)AI /빅데이터 전문 기업 스텔라비전 개발자 (21~23)
-------------------
[교육 및 강의]
삼성SDS LLM프로그래밍 교육(’24.09~10, 삼성U 멀티캠퍼스)
RAG 및 LLM 트렌드 강의 (’24.07, 마소캠퍼스)
랭체인Langchain을 활용한 LLM 챗봇 만들기(feat.ChatGPT)(‘24.06~, 인프런)
연구자와 대학원생을 위한 감성분석 기법 실습(‘24.04~, 인프런)
파이썬을 활용한 텍스트 분석(‘23.08~ 탈잉, '24.03~, 서울과학기술대학교)
파이썬 초보자를 위한 주가 데이터 분석 입문(‘23.12~, 인프런)
ChatGPT를 활용한 파이썬 기초강의(‘23.09~11, 경기대학교)
빅데이터 분석 기초 강의(‘23.08~, 렛유인에듀)
ChatGPT로 배우는 파이썬 기초 문법(‘23.07~, 인프런)
파이썬을 활용한 앱리뷰 분석(‘23.06~, 인프런)
쉽게 따라하는 LDA & 감성분석 빅데이터 논문 작성법 with ChatGPT (‘23.06~, 인프런)
텍스톰(Textom)을 활용한 텍스트마이닝(연구동향, SNS) 논문 작성법 강의(‘23.02~, 인프런)
단국대학교 빅데이터 전문가 과정 특강(’22.08, 단국대)
이외에도 다수의 개인 강의 진행
# 텍스트마이닝 논문 작성 기법/LLM 관련 강의 누적 수강생 수 2000명 이상 (타교육사이트)
# 국내외 인문사회 과학 분야의 방법론으로 쓰이는 텍스트마이닝 기법은 누구나 쉽게 익힐 수 있습니다. 국내외의 TopTier학회지에 텍스트마이닝/빅데이터 논문을 직접 쓸 수 있을 정도로 강의 및 컨설팅 가능하며 제게 배운 분 중에 몇 분은 크몽 전문가로도 활동하고 있습니다!
#해피AI는 기업체,기관 교육을 위한 데이터 분석,자연어처리, LLM, ChatGPT 관련 강의도 진행하고 있습니다.
[블로그]
AI 자연어처리, 텍스트마이닝 전문 N블로그 운영(해피AI 이진규)
[유튜브]
자연어처리 전문 유튜브 운영 (해피AI 이진규)
-------------------
텍스트마이닝/빅데이터/자연어처리를 처음 접하시는 분들 중 많은 시간을 허비하고
다양한 검토를 하다 결국 본 서비스를 선택한 클라이언트들이 200개가 넘습니다.
요즘 트렌드라 파이썬도 잘못하는데, 어려운 자연어처리, 텍스트마이닝을 배우느라 타 분야 연구원, 대학원생 분들은 많은 스트레스를 받습니다.
데이터에 대한 정확한 이해를 바탕으로 한 전처리가 되지 않는다면 안타깝게도 결과가 왜곡될 수 밖에 없습니다.
-------------------
검증된 전문가에게 맡겨서 "고품질"의 결과물을 받으세요.
삼성전자
한국데이터산업진흥원(K-data)
경기연구원
서울대학교
이화여자대학교
서울디지털재단(SDF)
한국대기환경학회
한국보건의료연구원
서울기술연구원
청운대학교
충북대학교
세종대학교
목포대학교
전남대학교
데이원컴퍼니
오므론헬스케어
인피플컨설팅
국립공원관리공단
한국직업개발원
대기업, 정부산하 연구기관, 대학교, CEO가 본 서비스를 선택한 후 만족하셨습니다.
국가기관 연구원 근무등을 비롯해 다년간 수많은 기업,정부기관과 경영,정책,복지,문화, 관광,간호 등 여러 분야에서 학술연구 를 목적으로 한 빅데이터 및 자연어처리 융복합 프로젝트를 진행하였습니다.
또한 석사는 "인문학",박사는 "공학"전공 이어서 누구보다도 타 분야에서 계신 분들의 입장을 잘 이해하고 있습니다.
"고품질"의 최신 NLP 기술을 적용해 빅데이터/LLM 논문의 고민을 제거해보세요.
매일 ACL 등 세계 최고 권위 학회지의 최신 트렌드를 분석하고 연구 중에 있습니다.
기본적인 방법(빈도,Tf-idf, LDA 등) 는 물론 최신 생성AI 트렌드 기법도 제공해 드립니다.
다른 연구자와 차별화된 "고품질"의 기술로 인정받는 연구자가 되도록 해드립니다.
다년간 수백 건의 데이터 정제과 분석경험으로 데이터의 가치를 이끌어내도록 도와드립니다.
빅데이터나 AI는 컴퓨터공학,통계학 등 기존 학문에 치우친 것이 아닌 융합이 필요한 분야입니다.
다양한 융복합 연구 개발 경험에서 얻은 데이터의 특성 기반 맞춤형 기법을 적용해드립니다.
참고로 저는 자연어처리 분야에서 편향된 데이터의 조정해 정확도를 높이는 방법 관련 연구를 진행하고 있습니다.
깊은 통찰과 경험에서 얻은 유기적인 분석기법 적용
텍스트 데이터를 마이닝하는 방법에는 수십가지가 있습니다.
이 방법들은 구글링이나 책을 통해서 공부한다면 누구나 적용할수 있지만
수십가지의 분석 기법들의 장단점을 파악하고 유기적으로 적용해서
데이터에서 중요한 의미를 끌어낼 수 있는 전문가는 많지 않습니다!
데이터에 특성에 따라 적합한 분석 방법을 설계해서 "한차원 높은 깊이 있는 결과물"을 드립니다.
데이터 특성에 따른 다양한 분석 파이프라인 설계 예시
1. A분야에 대한 국내 연구동향 분석시(13단계의 분석 적용)
- 데이터 특성에 맞게 시계열분리->데이터 정제-> 빈도,연관어분석->핵심어추출-> 핵심어 연관어 분석->핵심어를 포함한 데이터 필터링->핵심어를 포함한 데이터에 대한 빈도,연관어분석->토픽추출->토픽별 문서 비율추출->토픽 구성 단어에 대한 연관어 도출->시계열별 토픽분석적용->시계열별 토픽별 문서 비율추출-> 시계열별 토픽 단어에 대한 연관어 도출
2. B분야에 대한 국외 연구동향 분석시(11단계의 분석 적용)
- 데이터 특성에 맞게 시계열 분리->빈도 ->TF-IDF분석->카테고리별 빈도->카테고리별TF-IDF분석-> 동시출현 단어 분석->네트워크 중심성분석->클러스터링 분석->카테고리별 데이터에 대한 연결중심성분석->클러스터링 분석
3. C분야에 대한 언론기사 인식 분석시(13단계의 분석 적용)
- 시계열별 데이터 정제->빈도 분석->연관어분석->시계열별 차별단어 파악->특정주제추출->특정주제에 맞는 데이터 필터링->필터링된 기사에 대한 빈도분석->감성분석을 위한 사용자 사전 구축->감성분석 진행->토픽분석->문서별 토픽구성비율 도출->토픽별 차별단어 도출->차별단어에 대한 연관어분석(Word2Vec)
4. D분야에 대한 언론기사 보도 분석시(9단계의 분석 적용)
- 시계열별 기사 데이터 정제->시계열별 빈도 분석->시계열별연관단어분석-> N차 데이터 정제-> 특정 이슈 주제어 추출 ->이슈 기사 도출 기준 설정(기사증가량,기사언급수등)->특정 이슈 주제어에 대한 일별,주별 빈도변화량 계산->이슈기사 여부 판별>이슈기사 도출 기간 추출
직관적인 데이터 시각화 제공
논문 쓰신 분들은 아시겠지만
결과물를 알기 쉽게 잘 표현하는 것도 중요합니다
결과물이 좋아도 시각화가 직관적이지 않으면 이해할 수 없습니다.
대기업, 정부산하 연구기관, 대학교수분들이 선택한 이유가
정확한 결과물과 함께 직관적인 시각화도 제공하기 때문입니다.
(참고로 디자인 분야 분들도 다수 의뢰 주셨습니다!)
-------------------
전 직장에서 인문사회학적인 연구를 하다
우연히 자연어처리 프로젝트를 시작하였습니다.
처음엔 정말 많은 시행착오를 겪었습니다. 아무리 해도 결과값이 이상한데...
무슨 기법, 어떤 언어 모델을 써야 하지?? 등등 정말 막막했습니다.
기법들을 적용해도 원하는 결과와 다르게 나오 걸 보며 많은 한숨을 쉬었지만
결국, 분석모델과 데이터를 여러번 돌려보며 몇날을 고민 끝에 해결 하였습니다.
이후 몇 년간 여러 프로젝트를 거치며 실력이 쌓이면서 크몽 서비스를 오픈하게 되었습니다.
저의 초심자 시절 때 처럼 혼자선 막막하고 극한인 상황일 때 누가 옆에서 가이드 해줄 수 있는 분이 있었으면 좀 더 수월하게 프로젝트를 완료할 수 있지 않았을까?
처음 접하시는 분이나 잘 모르는 분들에게 가이드가 되어 줄 수 있다면 정말 편할텐데? 라는 생각을 하며 서비스를 오픈하였습니다.
항상 저의 초심자 시절을 생각하며 의뢰해주시는 고객분들에게 최대한 가이드 해드리고자 합니다.
-------------------
[상품 상세설명]
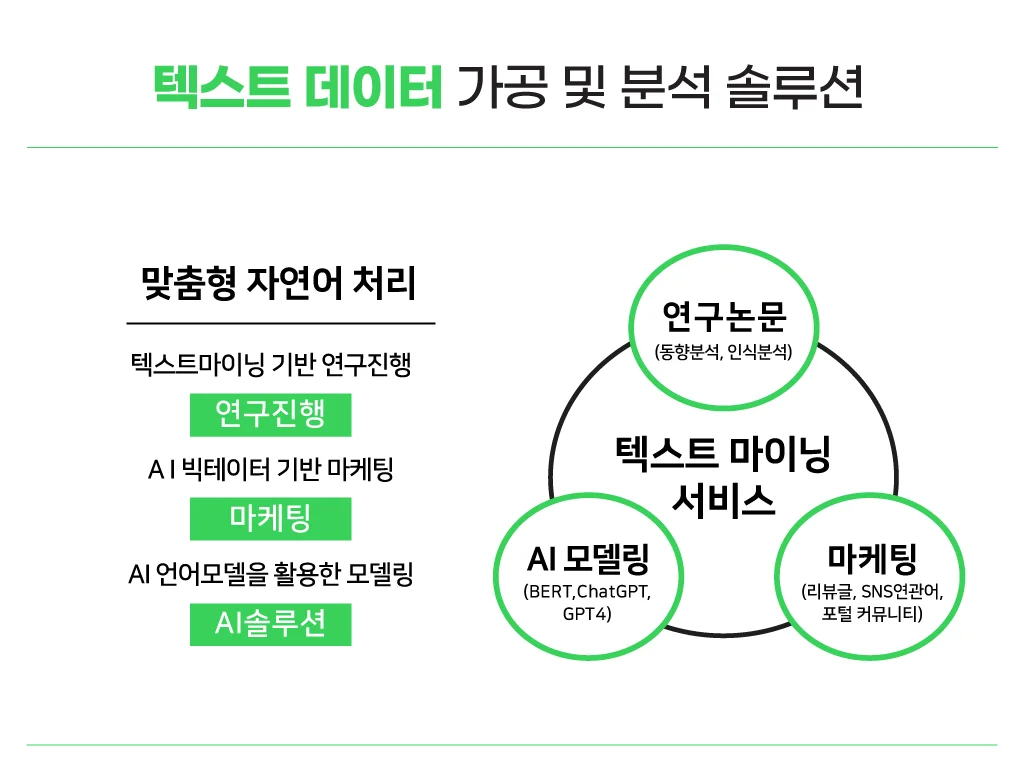
1) 빅데이터 및 텍스트마이닝 논문 컨설팅
(연구동향 ,블로그 및 카페,설문지분석 등 논문 수차례 진행)
-인문사회학, 예술 등의 빅데이터 논문에 tf,LDA 등 전통적 기법과 ChatGPT 등 생성 AI모델을 융합한 최신 트렌드의 기법 적용
- 전체기간부터 연도별, 특정기간까지, 세밀한 시계열 분석으로 특정 분야의 연구 동향과 인식을 명확히 파악 가능 (SCI급 TopTier 수준의 깊이 있고 꼼꼼한 시계열 데이터 분석 가능)
- (포트폴리오1)https://kmong.com/@LeeJinKyu/portfolios?portfolio_id=21858
- (포트폴리오2)https://kmong.com/gig/345782?portfolio_id=21938
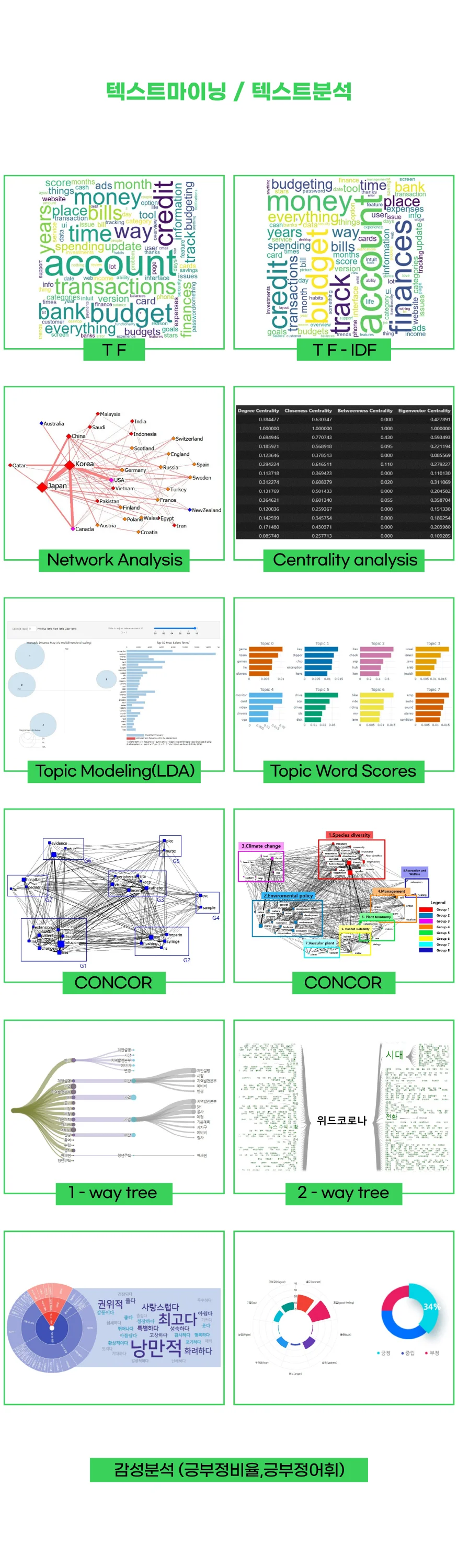
주요 분석 기법
- 국내학회 KCI용 : 빈도(tf), Tf-IDf, DoV, 워드 크라우드 등 rank기반 텍스트 분석
->SCI논문용 : DF, DFRatio,DoV, DoD,DoVIncPrev,DoDIncPrev, DoVIncRat, DoDIncRate,DF-ExtraIDF,ExtraSumTF,ExtraDF,ExtraDFRatio등 심화 Rank 분석 도출
- 동시출현단어,n-gram,네트워크 중심성 분석(근접, 연결, 매개,위세)
- 데이터 특성을 고려한 토픽모델링(Topic modeling)
(1) 머신러닝 기반: LDA(전문), DTM(DynamicTopicModeling),CONCOR,t-SNE,k-means 등
->SCI논문용: LDA+TF-IDF, LDA+TF,LDA+감성분석,LDA+Word2Vec,LDA+WordRatio 등 LDA(DTM)와 여러 혼합 기법 제공 가능
->타 서비스와는 달리 LDA (Latent Dirichlet allocation) 고급테크닉 적용(TopTier 학회지에 쓰이는 심화기법)
(2) 언어모델 기반: Word2vec clustering,BerTopic 등
2) 감성분석(긍정/부정 비율, 긍부정어휘 추출 등)
- 감성사전 기반 :KNU(한글),TextBlob,AFINN,VADER,Textom 등
->사용자감성사전 구축 가능(형태소 분석을 통해 감성사전을 구축해드립니다!)
->긍부정비율,긍부정어휘,긍부정점수,긍부정문서길이 등 탑티어 학회지급 상세 통계 가능
- 머신러닝 기반: 나이브베이즈 분류(Naive Bayes Classifier)
- (최신기법)AI모델 기반: BERT,LSTM,CNN,챗GPT, 최신 LLM등을 활용한 감성 분석
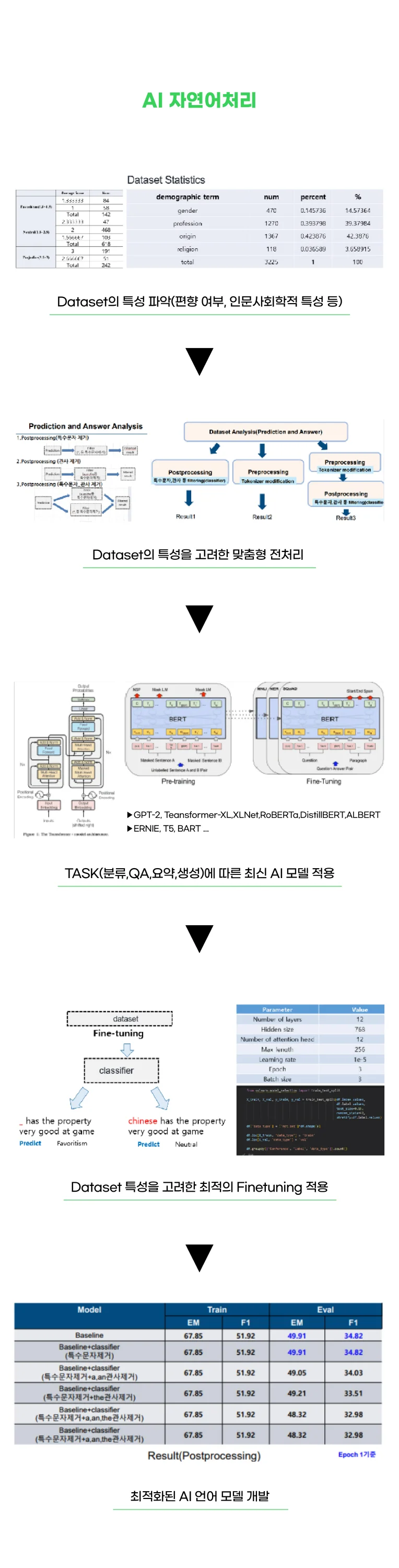
3 )ChatGPT 등 최신 LLM을 활용한 논문 컨설팅
->인문학,예체능 등 타분야에서 LLM모델을 활용한 연구 논문 컨설팅(프롬프팅 설계 등)
4) LLM 모델 개발 및 연구적용(파인튜닝,로컬모델 등)
* 고전부터 최신까지 다양한 기법 및 언어모델별 결과 제공 및 비교 가능
- 머신러닝 : LogisticRegression ,GradientBoosting,SVC,NB 등
- 고전 언어모델: Tf-IDF,Word2Vec,CNN, RNN,LSTM,BiLSTM,BERT 등
- 최신 언어모델: ChatGPT,Llama2, Falcon 등 한국어 리더 보드 모델 등
이 밖에도 다양한 자연어처리/텍스트마이닝 관련 기법을 제공합니다.
-------------------
[추천대상]
- 빅데이터/텍스트마이닝 논문 작성이 어렵거나 도움이 필요하신 분 (언론보도, SNS,설문지, 연구동향 관련 논문 수차례 진행, Toptier학회지 분석 기법 적용)
-학술 논문 동향분석,소셜 미디어 SNS에서 특정 이슈 분석하고 싶으신 연구자,대학원생
- 연구과제에 텍스트 마이닝, 빅데이터 분석, LLM모델링이 필요한 연구기관, 대학교
- 타 분야에서 LLM 모델과 같은 생성AI를 융합한 연구논문 작성이 필요하나 막막하신 분
- 사업계획서 및 제안서에 빅데이터 분석 및 시각화 등이 필요하신 대표님
- 상품 마케팅을 위한 고객의견(리뷰)등을 정밀하게 분석하고 싶은 대표님
저와 함께 데이터 분석 및 연구 경험이 많은 동료와 팀 프로젝트로 진행합니다.
-------------------
[주요 프로젝트]
- 첨단바이오 분야 LLM-AI 활용을 위한 관련 데이터 전처리, 연계 기능 구현('24.10~
한국과학기술정보연구원,KIST)
- LLM 기반 텍스트 마이닝을 활용한 복원 관련 용어 빅데이터 분석 (2024.08~11, 국립산림과학원)
-Private LLM기반 RAG 챗봇 모델 구축 ('24.07~10 한국전력공사)
- LLM 기반 빅데이터 분석 기법을 적용한 설문 데이터 분석 ('24.06~ 10 경기도교육청)
- LLM 기반 빅데이터 분석 솔루션 프로그램 개발 ('24.07~ 10 솜뭉치빌런즈)
-빅데이터 분석 기법을 통한 이용자 설문 데이터 분석 및 시각화('24.05, 코멘터리 사무소)
-내부망 전용 LLM을 활용한 텍스트마이닝 솔루션 개발('23.07~'23.11, D 정부기관)
- 빅데이터 분석을 통한 한우시장 트렌드 분석('23.08~24.01, 이화브리오)
-Instruction Tuning 및 강화학습(RLHF)을 통한 LLM모델 개발('23.07~11, 서울디지털재단)
- AI언어모델 기반 헬스케어 서비스의 사용자 리뷰 텍스트 분석('23.05~06, 삼성전자)
- 단어임베딩 유사도를 활용한 Word2Vec 언어 모델 기반의 텍스트마이닝 기법을 활용한 설문 빅데이터분석 ('23.05,정림건축)
- AI언어 모델 기반 텍스트마이닝 기법을 활용한 C대 및 K대학교에 대한 SNS인식분석 ('23.04~05, LMC)
- 자연어처리 기술 기반 텍스트마이닝을 활용한 한국대기환경학회 연구동향분석 ('23.03,대기환경학회)
- AI 모델 kopatBERT기반 논문 QA 모델 개발('23.02,한국기술마켓)
- 자연어처리 기법을 활용한 설문 질적연구 자료 분석('23.01~02,청운대학교)
- AI 모델 kopatBERT기반 논문 분류 모델 개발('23.01~02,한국기술마켓)
- 딥러닝 기반 토픽모델링을 활용한 법학 설문 빅데이터 분석('22.12~'23.01,서울대학교)
- 딥러닝 및 머신러닝 기반 텍스트 분석 기법을 활용한 간호 설문 질적연구 자료분석
('23.12~02,충북대학교)
- KorQuad를 활용한 BERT 기반 금융권 QA task 모델링('22.12,B사)
- 학술 데이터의 특성에 따른 Bert기반 Multi-classification 모델 개발('22.11, A사)
- 인공지능 자연어 처리(NLP)분야에 대한 최신 트렌드 및 기술 경향 분석('22.11, Textom)
- AI모델 Word2Vec 및 TF기반 의료설문 빅데이터 Keyword 추출 알고리즘 개발
('22.10~11,D사)
- AI모델 Word2Vec과 감성분석을 적용한 설문문항 빅데이터 분석 ('22.10~11,경기연구원)
- 딥러닝 기반 비대면 진료 관련 언론기사 토픽 분석('22.08~10,한국보건의료연구원)
- 언론보도 분석을 통한 캠핑 트렌드 인사이트 도출('22.08~09,한국관광컨설팅)
- AI모델 RNN기반 리뷰 인사이트 추출 및 분석 프로그램 개발('22.03~07,서클플랫폼)
- 주요 언론사 빅데이터 분석을 통한 안전사고 유형분석('22.07, 서울기술연구원)
- 뉴스 빅데이터 분석을 통한 '나는 SOLO' 인기 요인 분석('22.06, Textom)
- 우크라이나 러시아 전쟁에 대한 국민인식 분석('22.04, Textom)
- 주요 도서 카테고리별 크롤링 프로그램 개발 및 빅데이터 분석(’22.03~ 10데이원컴퍼니)
- AI모델 Word2Vec기반 텍스트마이닝 솔루션 프로그램 개발('22.03~07,서클플랫폼)
-데이터 인력 분석을 위한 정보 수집 프로그램 개발 및 빅데이터 분석(’22.02~04, 한국데이터 산업진흥원(K-data))
- 헬스케어 스토어 상품 리뷰 분석(’21.02-’21.03,오므론헬스케어)
- '00 기업 인터뷰 설문 빅데이터 분석'(’22.03, 인피플컨설팅)
- 빅데이터 분석을 통한 여성원피스에 대한 니즈 분석('22.02, Textom)
- NLP기법을 활용한 정맥간호 관련 인식 분석('22.01~ 12 울산대학교)
- 빅데이터 분석을 통한 인공지능에 대한 언론 보도경향 분석('22.01, Textom)
- 빅데이터 분석을 통한 축산물 트렌드 파악 및 분석(’21.12~'22.01, ㈜중원푸드)
- 빅데이터를 활용한 2022년 국립공원 탐방 키워드 분석(’21∼’22,국립공원관리공단)
- 빅데이터 분석을 통한 재테크에 관한 언론보도 분석(’21.11,Textom)
- 쇼팽 콩쿠르에 대한 언론보도 동향 분석(’21.10,Textom)
- 월드컵최종예선에 대한 국민인식 분석(’21.10,Textom)
- 위드코로나에 대한 국민인식 분석(’21,Textom)
- (언론보도자료)빅데이터를 통해 본 국내 주요 숲길의 인기 비결(’20,국립산림과학원)
- (언론보도자료)빅데이터가 말하는 인제 자작나무 숲의 인기 비결(’19,국립산림과학원)
- 빅데이터 분석을 통한 숲길 네트워크 구축 및 관리방안 도출 연구(’20,국립산림과학원)
- 해외 휴양공간 빅데이터 제공 시설 구성요소 및 위계 분석을 통한 정보 서비스 체계 구축
(’20,국립산림과학원)
- 빅데이터 분석을 통한 산림휴양공간 핫스팟 지역 수요 예측 및 관리 기술 개발(’20,국립산림과학원)
-국내 주요 산림휴양공간별 빅데이터 분석을 통한 네트워크 체계구축 및 중·장기 운영관리 로드맵 제시(’19∼’20,국립산림과학원)
- 데이터 마이닝을 통한 산림 휴양공간 이용자 인식 도출 및 운영관리방안 설계(’19∼’20,국립산림과학원)
- GIS공간데이터 및 비정형 텍스트 정보 자료 분석을 통한 DMZ숲길 최적 노선 기술 개발 및현장 적용성 검토('18,국립산림과학원)
이외에도 다수의 공공기관,기업체와 개인적 의뢰 등 총 200건 이상 프로젝트 진행
[텍스트마이닝 및 NLP 관련 논문 ]
Vanilla 프롬프팅 기법과 CoT 프롬프팅 기법 간 음악 편곡 결과 비교 분석
이진규 외 1인| 게임학회|2024.02
언론기사 빅데이터 분석을 통한 대규모 언어모델에 대한 기술 인식 분석: ChatGPT 등장 전후를 중심으로
이진규 외 1인| 한국멀티미디어학회|2024.02
https://drive.google.com/file/d/1hX5tRHzcLSwKk1a5UKrA_T67xVMk4JR5/view?usp=drive_link
정맥간호 인터넷 카페 Q & A 게시글의 키워드 네트워크 분석
이진규 외 1인| Healthcare Informatics Research |2023.02
https://drive.google.com/file/d/1lLkrD2v3RXZe0F0zRMeggcS1unfCKS--/view?usp=share_link
자연어 처리(NLP)기반 텍스트마이닝을 활용한 소나무에 대한 국내외 연구동향(2001∼2020)분석
이진규 외 1인| 농업생명과학연구|56(2)|pp.35~47|2022.04
https://drive.google.com/file/d/1yOWp48E4xvuARp1Vxi4BychCsQVVxvqf/view?usp=share_link
텍스트마이닝을 활용한 백두대간에 관한 연구동향(2001‒2020) 분석
이진규 외 1인 | 한국산림과학회지|111(1)|pp.36~49|2022.03
https://drive.google.com/file/d/1IX34CV2cQ06aiZzag2gStvaGfU1NsfCb/view?usp=drive_link
텍스트마이닝을 활용한 국내 산림생태 분야 연구동향(2001‒2020) 분석
이진규 외 1인|한국산림과학회지|110(3)|pp.308-321|2021.09
https://drive.google.com/file/d/1ewHBl7FWIpxm9qNqwxQ9BL4jEQbpqYgk/view?usp=drive_link
(NLP) 편향(Bias) 완하를 통한 감성 상식(Commonse)문장 생성 향상 기법 연구 (BART모델 사용)
https://drive.google.com/file/d/1oNODMI2wv5zN-d-On7bnct9tsi5jL0Vl/view?usp=share_link
숲길에 대한 10 년간의 언론 인식분석-텍스트 마이닝 분석을 중심으로
이진규 외 2인| 산림경제연구|28(1)|pp.1-19|2021.06
산림관광지로서 인제 자작나무 숲에 대한 소셜미디어 이용자 인식 연구
이진규 외 2인| 한국산림휴양학회|24(3)|pp.65-81|2020.09
이외에도 타 분야에서 다수의 학술논문, 학술발표, 연구보고서 등의 성과창출
[데이터 분석 언어]
- Python
- 의뢰인으로부터 요청사항 전달 -> 금액 및 기간 협의 ->프로젝트 착수(3~7일)
- 데이터 분석/프로젝트 목적을 상세하게 말씀해 주시면 좋습니다.
- 분석 데이터의 유무(데이터가 없을 시 크롤링 진행)
기술 수준
팀 규모
상주 여부




패키지 별 주요 특징을 비교해 보세요
STANDARD
150,000원
DELUXE
700,000원
PREMIUM
5,000,000원
패키지 설명
(고급)텍스트마이닝/자연어처리
- 기본적인 텍스트마이닝/ 텍스트 분석 및 해석 - 자연어처리 모델
(고급)텍스트마이닝/자연어처리
- 데이터정제 N번(SCI급고품질) - AI텍스트마이닝논문(데이터+해석+시각화) - AI자연어모델링(LLM)
기업/기관 빅데이터분석 및 AI개발
- 기업/기관용 AI기반 텍스트 마이닝 및 빅데이터분석(연구보고서,연구과제), LLM모델링(챗GPT,llm)
분석
1개
1개
1개
작업일
4일
4일
30일
수정 횟수
3회
3회
3회
총 작업개수
256건만족도
100%회원구분
기업회원세금계산서
발행가능안녕하세요 해피AI 대표 이진규 입니다. 다년간 데이터 분석 및 연구개발 경험이 많은 동료와 함께 프로젝트를 진행 합니다. (현)생성형AI 및 빅데이터 분석 전문기업 해피AI 대표(24~) (현)AI대학원 박사수료(자연어처리/llm 전공) (전)AI 및 빅데이터 분석 전문기업 스텔라비전 (전)국가기관 연구소 빅데이터 /자연어처리 연구원 (전)빅데이터솔루션 업체Textom Analyst
수정 시 각 항목 1개에 대해서만 진행합니다. (예: 단어빈도, Tf-IDF,LDA 등 각 개별 항목들) 수정범위는 도표와 문구 등에 한하여 진행됩니다.
가. 기본 환불 규정 1. 전문가와 의뢰인의 상호 협의하에 청약 철회 및 환불이 가능합니다. 2. 작업이 완료된 이후 또는 자료, 프로그램 등 서비스가 제공된 이후에는 환불이 불가합니다. ( 소비자보호법 17조 2항의 5조. 용역 또는 「문화산업진흥 기본법」 제2조 제5호의 디지털콘텐츠의 제공이 개시된 경우에 해당) 나. 전문가 책임 사유 1. 전문가의 귀책사유로 당초 약정했던 서비스 미이행 혹은 보편적인 관점에서 심각하게 잘못 이행한 경우 결제 금액 전체 환불이 가능합니다. 다. 의뢰인 책임 사유 1. 서비스 진행 도중 의뢰인의 귀책사유로 인해 환불을 요청할 경우, 사용 금액을 아래와 같이 계산 후 총 금액의 10%를 공제하여 환불합니다. 총 작업량의 1/3 경과 전 : 이미 납부한 요금의 2/3해당액 총 작업량의 1/2 경과 전 : 이미 납부한 요금의 1/2해당액 총 작업량의 1/2 경과 후 : 반환하지 않음
빅데이터/텍스트마이닝 논문을 쓰고 싶은데 어떤 분석법을 적용할지 모르겠어요.
분석 목적, 개요, 연구주제 등을 말씀해 주시면 알맞은 분석 법을 추천해드립니다.
가지고 있는 데이터가 없는데도 분석 가능한가요?
데이터가 없으시다면 공공데이터, 웹사이트 크롤링을 통해 분석 가능한지 상담해드립니다.
저는 텍스트마이닝,빅데이터,인공지능을 전혀 모르는 초보라 물어볼게 많아요
친절하게 설명해 드립니다. 본 서비스만는 개인과외 같은 1:1 상담 서비스 제공이 장점입니다.
챗GPT,한글LLM 등 최신 AI모델을 활용한 융합 연구를진행하고 싶어요.
원하시는데 연구 문제에 맞게 활용할 수 있는 인공지능/자연어처리 모델을 개발하고 데이터를 분석해드립니다.
| 서비스 제공자 | LeeJinKyu | 취소/환불 조건 | 취소 및 환불 규정 참조 |
| 인증/허가사항 | 상품 상세 참조 | 취소/환불 방법 | 취소 및 환불 규정 참조 |
| 이용조건 | 상품 상세 참조 | 소비자상담전화 | 결제 전 상담 제공 |
5.0
(200)








